Database Fundamentals

In one of my earlier blogs: 5 Essential Technical Skills for Data Analyst, I said that SQL is one of the key skills to learn as a data analyst and data science. Both roles require working with databases a lot. In my current role as a data analyst, I haven't had to interact and work with databases until recently. By that, I mean using a database management system (DBMS) to retrieve data using SQL. Until now, I've gathered data the traditional way, extracting information from various applications like CRM, websites etc.
Starting in the last few years, the industry I work in has been undergoing digitalisation. You may be thinking, geez, which industry is she in? It's so behind! You're not wrong. I concur that the healthcare and pharmaceutical industry, without a doubt, is late to the party!
Many companies are democratising data as part of digitalisation, a fancy term for the ongoing process of enabling people in an organisation to work with data. This movement is great. In my opinion, it has given our team access to our company's database. Previously it was reserved for IT.
Since having access to our company's database, my motivation to learn SQL and understand the database fundamentals have increased. It makes not only learning this topic more meaningful, but I can now apply what I learn at work!
In this blog, I want to share database fundamentals with you, a view from the sky. It's intended for beginners. Drawing from my journey of learning about this topic, I find learning database fundamentals simultaneously with SQL helpful in accelerating my understanding.
What is a database?
At its core, a database is an organised collection of data. Think of it as organised electronic filing cabinets. Data is kept in different structures or formats, depending on the type of database. One of the most common types is the relational database which stores data in a tabular form. Most enterprise companies have relational databases, and it's for this reason that I have chosen to focus on this type of database.
Something to note, when people speak of a database, they may be referring to DBMS, which are programmes that allow people to create and maintain databases. With DBMS, you can define a database and specify data types and constraints of the data to be stored, such as the column must not have empty records or each record must be unique. DBMS also enables applications to interact with the database and process queries. A query is a term used to describe a request for information. Oracle MySQL, MariaDB, Microsoft SQL Server, and Postgres are some common DBMS.
Relational Database Overview
I've alluded earlier that a relational database stores data in tables. Each table looks like an excel sheet with rows and columns. Tuples and fields are jargon you may hear; they mean rows and columns, respectively. Tables are used to organise closely related data together, for example, a table containing employee information, a table for orders, a table for customer information, a table for stores etc. you get the idea.
You may wonder why have data distributed across multiple tables? Why not have one big table with all the necessary columns. It has to do with eliminating redundancy and, therefore, efficiency in performance.
Let me explain. The table below is a list of library transactions. See how we have repeatedly repeated details like name, email and phone for the same customers. What happens if Chandler changes his email and phone number? We have to make changes in multiple rows in the table.
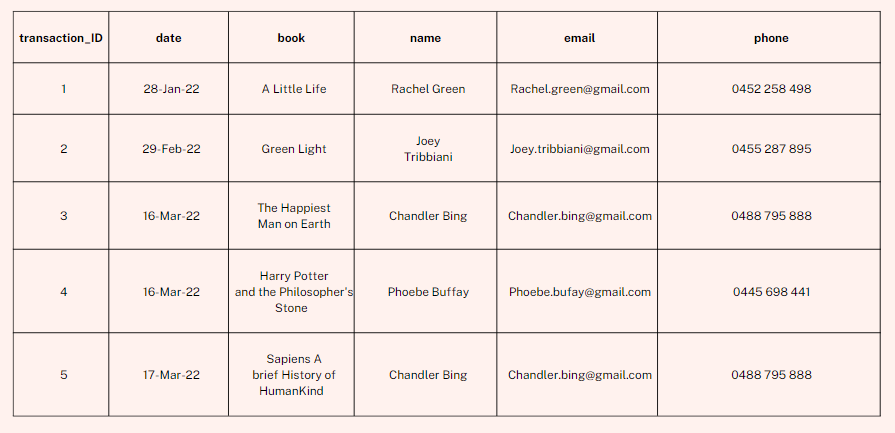
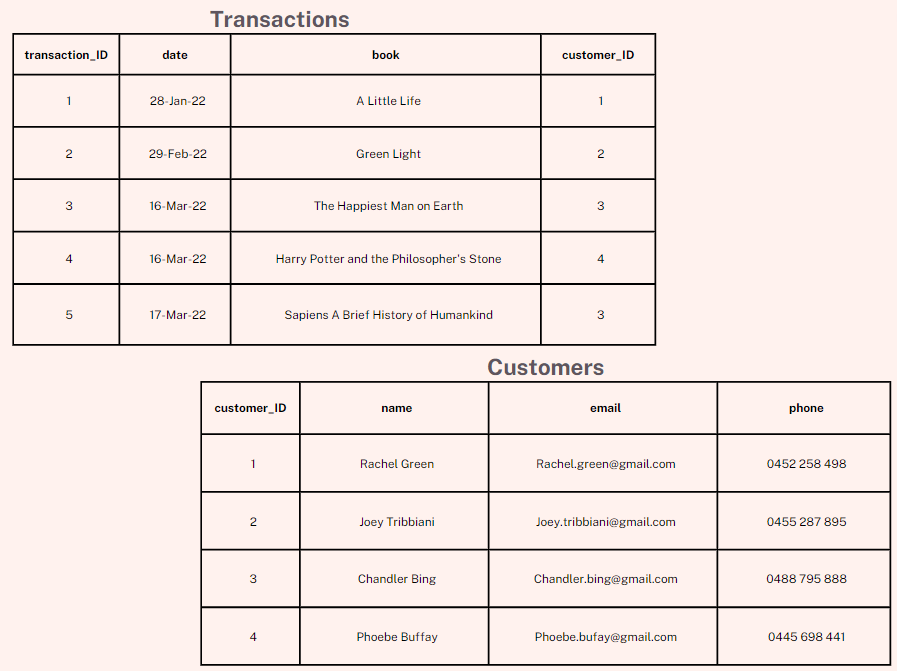
It's far more efficient if we split the table into a Transaction and Customer table and somehow have the tables "relate" to each other. I will explain how it's done a bit later. Now, with two tables, if Chandler changes his email or phone number, we just need to change one row.
Schema
Each database will have a predefined schema. It's like a blueprint that defines the design of the database. It describes how the data is organised, how the tables relate, and the data types stored in rows and columns. It also formulates all the constraints to be applied to the data.
This is an illustration of a database schema from Lifewire Tech for Humans

Keys
Now, let's talk about keys. Key is an important concept. Its purpose is to help uniquely identify each row in a table. There are many types of keys, seven broad types, I don't understand all of them, but based on what I have read, the two that you'll need to know and understand are Primary Key (PK) and Foreign Key (FK).
PK refers to one or more column of a table that helps identify all the records uniquely present in a table. With PK, it cannot consist of the same values repeated multiple times. Each row must have a different value. Another constraint of PK is that it cannot have a null value. A null value is a special marker indicating that data in a column is unknown or missing.
When PK from one table appears in another table, it is called FK. FK links tables and establishes dependencies between tables.
The table with the FK is called the child table. The table with the PK is known as referenced or parent table.
Let's look at the two tables below to understand this better.
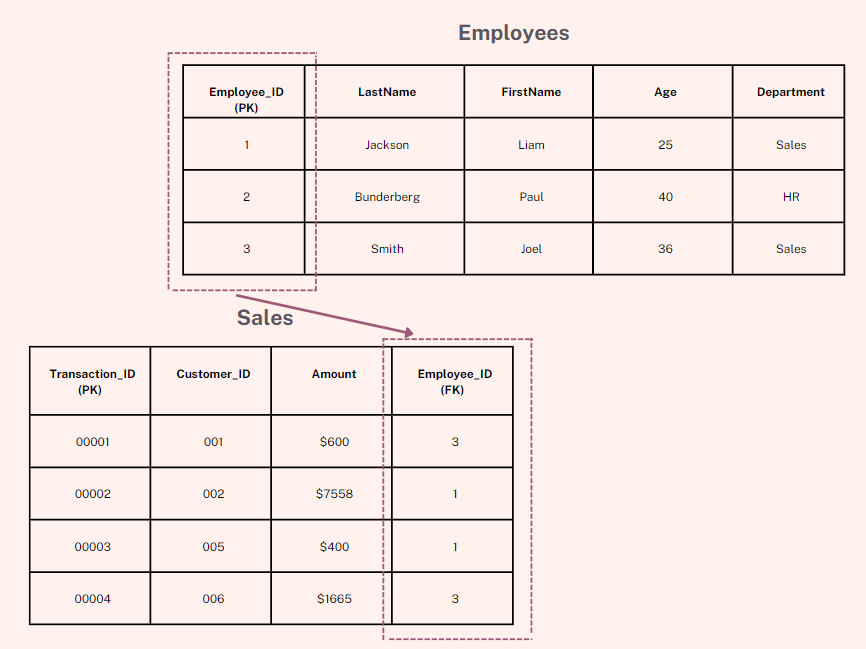
Notice that the "Employee_ID" column in the "Employees" table points to the "Employee_ID" column in the "Sales" table.
The "Employee_ID" column in the "Employees" table is the PRIMARY KEY in the "Employees" table.
The "Employee_ID" column in the "Sales" table is a FOREIGN KEY in the "Sales" table.
That's the essence of the relational database. It's widely popular because of its ability to create meaningful information by joining tables. I'll leave you with a short video that rehashes the basics of the relational database.